How Lemino.AI was built by a master procrastinator
How lemino.ai was created by a bored engineer and a horror story of procrastination.


I once asked a question, that led me to work on lemino.ai for months utilizing my free time during weekends. I bought the domain much earlier that resonates with the phrase "Let me know".
As a busy technology guy working on daily hustles at TallyKhata while driving a technical vision to better serve millions of MSME users in Bangladesh, I hardly get time to work on something personal. Though deep in my heart I'm still a purist engineering nerd who cares more about answering deep technical questions than solving real world business problems. Which is quite an opposite character an ideal CTO should have.
It's like the instant gratification monkey described by Tim Urban. So every morning in weekdays, like a rational decision-maker, I try to reset myself to become a better CTO. But every night and weekends, deep inside that engineering mind, that monkey takes over my thoughts, who wants to build something hands on that may answer a silly technical question with zero business viability.
So the silly question was:
Many frontier AI labs today are building LLMs based on hundreds of billions of webpages of common crawl as well as custom built large datasets with billions of parameter models using hundreds of thousands of GPUs to train. What if we could sort based on some criteria of educational quality and keep only the top couple of hundred million of these webpages and fine tune an existing open weight model like LLAMA? Will it perform better for educational queries asked by students or professionals?
I believe it will. Because of 2 reasons (hypothesis?):
Reason 1
Higher quality data may lead to better quality educational answers with less hallucinations. There is a well known phrase in machine learning that says "Garbage in garbage out". Our human brains are remarkably efficient in filtering garbage signals and so far the only working AGI system in this world is the human brain.
Hence I thought training a model with higher educational quality data, while filtering out the garbage may lead to better outcomes. You may already know how grounding works for LLMs. In general, grounding is a core function of intelligence, a process of connecting knowledge to the internal world model of an intelligent being. Similar to RLHF (Reinforcement Learning from Human Feedback) that was used to fine tune GPT3 to build ChatGPT, where there was a curated human feedback loop. What if we could make use of a somehow "curated" large collection of the whole internet for grounding an LLM while building a search engine?
In the process, we may also find out which base model weights / parameters are less important while predicting only higher quality data and prune them to reduce model size (may be) so it can be run in a laptop or even phone without compromising quality? Sounds promising right?
Okay, so first of all I found in huggingface, an open source high quality dataset fineweb that also has another variant dataset named fineweb-edu which already did create an educational quality classifier using annotations generated by LLama3-70B-Instruct. I said brilliant, someone has already created and open sourced what I need to start my experiments! And more importantly this is a manageable scale of just 1.3 trillion tokens, that translates to several terrabytes of indexed data that is approachable by me considering cloud costs.
Reason 2
It costs a lot of money to train, hence an existing open weight model would be easier to experiment and fine tune. LLAMA was an obvious choice at that time. But wait, I could only barely do inference of 13 billion llama3 model. I couldn't even train a 13B model on my setup and a 70B model is too big to even try. Though techniques like FSDP and QLoRA gave some hope, but that hope quickly faded away when I realised, that still requires a whopping 48GB card or at-least two 24GB GPU cards. So reality slapped in my face hard with a loud voice yelling at me: "You are GPU Poor, Stupid!".
OK I said, but I have access to cheap cloud GPUs from vast.ai. I rented some GPUs from there, did some experiment to fine tune LLAMA 3 with 400k bangladeshi news paper stories dataset, because fineweb-edu is still large, hence before training on it, I did experiment with a smaller, but more constrained subject matter dataset for a proof of concept to build a high quality Bangla news article generator.
Costing some hard cash, it turned out to be a failed run, because it seem to have overfit. Disappointed with the fine tuning results and lost money I stopped my experiments for few weeks and like a master procrastinator, started watching hours of Lex Fridman video podcasts talking to AI experts.
Inside the mind of a Master Procrastinator by Tim Urban
From one such podcast, I came to know failed runs are pretty normal and common accepted norm among experts in the frontier labs. So that gave me some hope and motivation to continue, but when global top tier experts in the subject are saying it needs them to go through many failed runs to perfect a model, and I know I don't have that luxury and expertise, I had to turn to simpler solutions like building RAG (Retrieval Augmented Generation) pipelines with the fineweb-edu dataset that gives me much more freedom to experiment with less cost. Then later on I can finetune when more confidence is gained.
The situation felt exactly as if I started with a moon shot ambition, while ending up catching fishes, just as depicted in the below image:
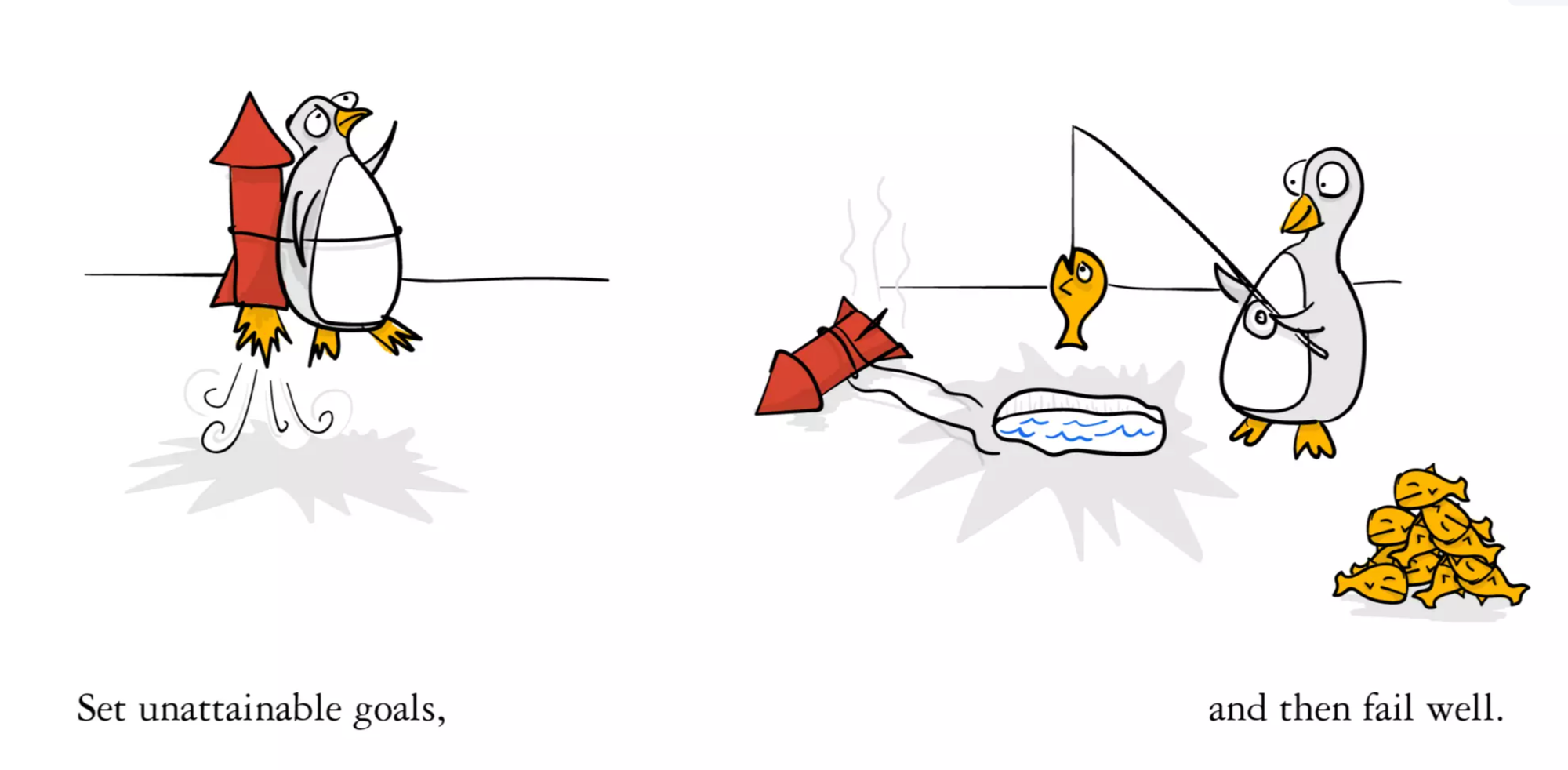
But as this image is actually How Google Works according to Eric Schmidt, so instead of disappointment, this sparked more energy of motivation for me.
Now after settling on to build a RAG pipeline, I first needed to build an index of the fineweb-edu dataset. Initial calculations told me that to build an index of a couple of terrabytes of text data, I should have at least 5TB size SSD on a cloud VM with a fare amount of RAM and CPU cores. That still deemed too costly for a "pet project" on any good cloud provider I knew. I looked at the pricing pages of AWS, Azure, Google cloud, Linode and many more, but cost seemed like a blocker.
After fare amount of research to reduce cost of vm, I discovered FranTech, a cloud hosting provider of ultra low cost that is giving away 6TB SSDs with VMs at an unbelievably low cost than everybody else. Frantech also has good reviews, so I jumped in. But my Bangladeshi dual currency card was declined at their checkout. Somehow, my bank thought it is a good idea to block such less known cloud hosting companies. I scratched my head with disappointment. Then something clicked my mind, I had some spare money received earlier for my work from sponsors in one of my open source projects on Cassandra database which was lying unused on a virtual non Bangladeshi card I had. So I used that card to solve the problem. Now I have access to a VM that I can build and serve my high quality index from.
So I built the first index with Milvas, a vector database that is known for it's semantic search capability. It supports approximate nearest neighbour (ANN) searches on high dimensional embedding vectors. Now I knew I need a good quality but more importantly free and fast document embedding model to create embedding vectors and index the embeddings for each fineweb-edu document into milvas. So I went to the MTEB leaderboard of open embedding models to find the model suitable for my needs.
After another round of research and experiments, UAE and MiniLM were found to be of good balance between accuracy and speed. So I created two small indexes with both and did some query experiments to measure the quality of the embedding. Also did some experiments with the age old Elasticsearch and the proven BM25 ranking algorithm. In my tests I found BM25 was giving more relevant results than the overhyped semantic search.
I knew it's not the fault of Milvas nor semantic search, because I have had experience creating large face embedding indexes with it in 2020 for building a large scale face search system, which worked remarkably well to match a person from video feeds to a face embedding database containing millions of face embeddings within milliseconds. Plus since then Milvas went ahead a long way too to become a leading vector database in the current AI hyped era. But unfortunately the quality of the open source text embedding models is not the best in class yet.
So contrary to the commonly suggested RAG architectures, I decided to switch back to the old school search system, Elasticsearch with BM25 for retrieval. Plus I found that ES has come a long way too and natively supports vector indexes as well. So for now I decided to stick with BM25, the old and proven search algorithm until open source embedding models improve. Embracing Elasticsearch in this case will also help me create a hybrid search system that can take advantage of both BM25 and semantic vector search from a single platform.
Then some day later, again Lex Fridman had a podcast with Perplexity CEO Arvind Srinivas, where he shared that they also have gone through the exact same experience and endorsed BM25. So I got the motivation again that I'm possibly on the right track. Much later on I discovered that DeepMind published an article in September 2025 about RAG that showed BM25 indeed works well for RAG use cases and also attempted to explain the scientific why behind it which is fascinating for a retrieval algorithm this old!
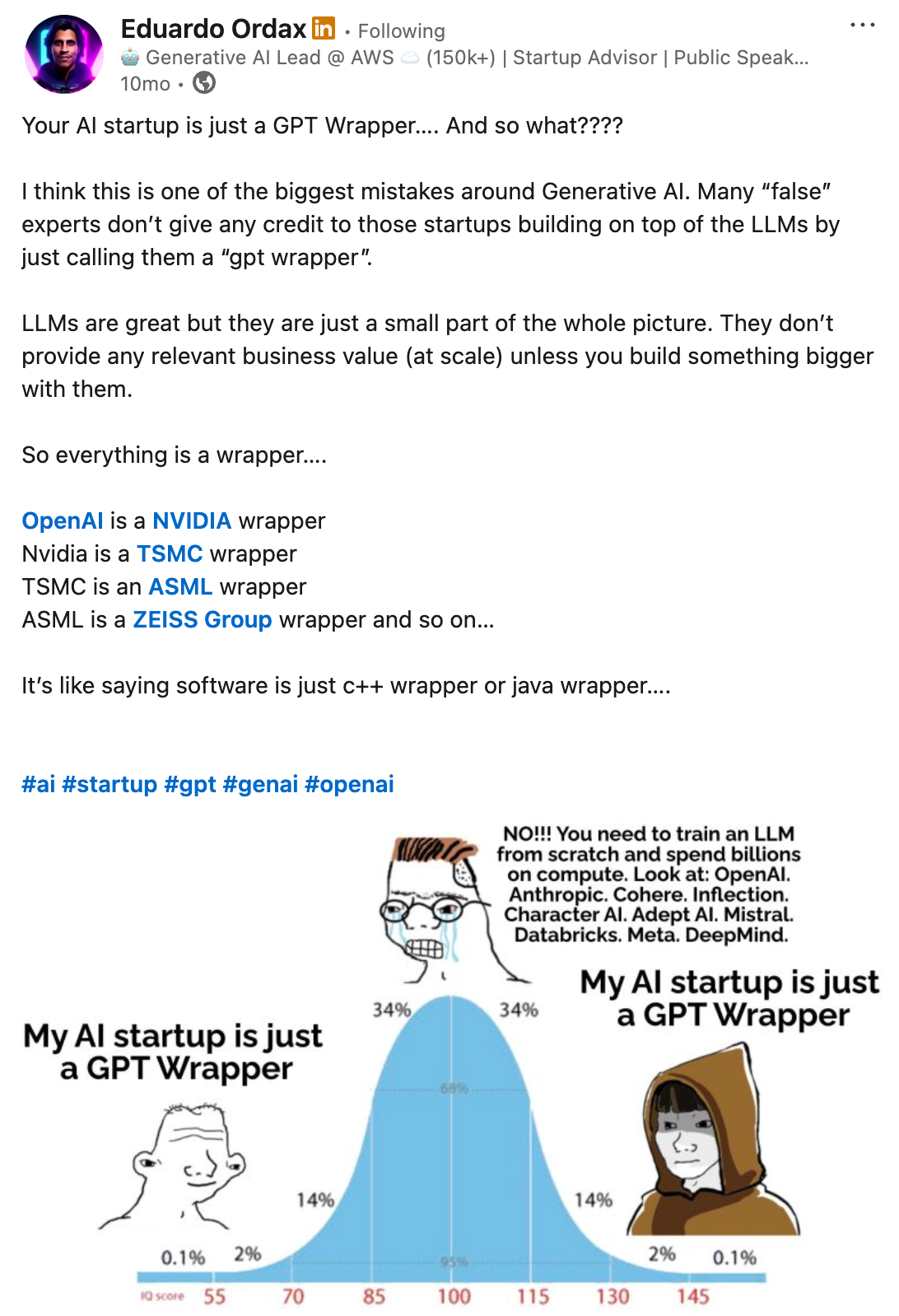
While doing these experiments and hard work to build my own search platform leveraging LLMs, I started to see multiple facebook / linkedin posts of the following nature:

It was initially discouraging for me to doubt whether I'm doing anything worthwhile. Honestly after all it felt like yet another LLM wrapper that I was building? But later on I realised if we think deeply enough, everything is a wrapper around something. Most of the recent successful AI startups are indeed wrappers over high quality base llm models.
At the end of the day what matters most is whether you're building something that creates value, something that your customers want. Eduardo nailed it very well in his Linkedin post.
So I built the full index. Now I have a high quality but small couple of terrabytes size index that I can technically and financially manage. But there is another problem. Each document contains plain text without any trace of header, section marker etc. Plus many documents, i.e. pdfs were large and finding the relevant section against the user query and pushing that part into the LLM context was not straight forward. So I tried two combined approaches to solve the problem:
1. Live Search, Crawl & Chunk
The first approach was to convert the user's queries and conversations into an efficient context aware search query that can be used to search the web to find relevant high quality results and process them through the following steps:
- Live search and crawl the resulting urls with playwright
- Process the resulting html / pdfs through beautifulsoup, docling and fastText
- Filter irrelevant content (ads, site/document headers, menu structure etc. through cascade of rule based filters and content heuristics)
- Convert the resulting clean document into markdown
- Chunk the markdown into smaller sections based on a heuristic parser
- Index the chunked documents into Elasticsearch for retrieval with BM25
- Find and push only relevant content chunks against the query into the LLM context for higher quality RAG
Through this process I discovered bugs and also contributed several fixes to some of the open source libraries I was using for extraction, a painful but fun learning experience. The technologies I've put together is now available as a reliable and simple to use URL to Markdown API so that everyone don't have to go through the same pain handling urls and pdf documents of their own.
Turn Any Webpage or PDF into Clean AI-Ready Markdown
2. Generate Relevant Questions
The second approach was to generate relevant questions against each document chunk using LLAMA3, so that if a similar question was asked by the user, the document chunk gets ranked higher in the query response against the index. Working on this approach made me realise that it's now technically feasible to create fully autonomous teaching assistants, that can disrupt the current edtech status quo. Perfect! I now got something new to procrastinate on!

While I was busy digging up (read procrastinating on) ideas for disrupting the edtech industry, DeepSeek was released and it blown away the AI world. So out of FOMO (fear of missing out), I had to get out of the edtech rabbithole and go dig into DeepSeek instead. It was a powerful open source model to be available to use. So I switched from LLAMA3 to DeepSeek-R1 for LLM inference and tuning.
DeepSeek FOMO helped me to get out into the real world from the edtech disruption rabbithole and restart building the UI for Lemino search index. To build the search UI, I found some open source templates to start with. With a small payment in design.com I created a good looking logo for the brand. After some tinkering with NextJS + Tailwind for the frontend and FastAPI for the backend, I finally built Lemino.AI and here it is. A low cost, glorified RAG based web search system leveraging open LLMs. The system also works well with Anthropic's Sonnet models to produce much better quality answers that are grounded based on search results. The system is tuned to refer resources from the web, leverage my high quality educational content index to provide better quality response and give the user a chance to verify the answers from it's sources.
While I'm still working on it and improving it every weekend, but I thought it's a good time to start getting feedback from the crowd. It will help me to stop procrastinating on youtube by watching AI sci-fi i.e. "absolute denial" and start being productive working on the system instead.
So please experiment with it, ask it what you want to know and share your valuable feedback with me. It will help keep my head inside reality and help me awaken the "panic monster" inside my head that only wakes up when a deadline is near or there's danger of public embarrassment.
Note that panic monster will magically help me to improve the system further, help me learn more, push me to experiment more. Because the instant gratification monkey is only scared by the panic monster. Also it helps me to finally take over and start asking sane questions like the following:
What's the business case for something like this, given Perplexity and ChatGPT DeepSearch exists?
Answer: For now I don't care. I love building and experimenting with things, maybe something will come out of my experiments some day that is business worthy and market fit. The future of healthcare, edtech or ecommerce? A better search product? or yet another failed copycat? I don't know. For now it doesn't even matter, I'm just learning and it is a lot of fun to learn things by doing. You know, the instant gratification monkey loves things that are fun and easy.
However, I've tried to share why I think it still matters to build Lemino. I'll also try to share the details of my learning and experiments over time. Note that the system is targeted to provide better educational content and will try to focus on that "broad niche" for now. Also I'm going to compile domain specific rich knowledge bases to create expert systems for specific professional fields to help professionals get better answers. The system may even autonomously do things for them like a "smart agent".
For example I've created a custom maritime knowledge-base for my brother who is a Marine Engineer, and it is already helping him navigate complex maritime regulations and safety procedures in his ship. Let me know what other professional fields I should target next? Some idea level candidates I have are as follows:
Candidate Idea 1
Helping doctors better serve their patients by indexing a medical knowledge-base of latest medical books, research articles and medicine index? Best experience I can think of is a mobile app that listens to the doctor-patient conversation and assist the doctor in diagnosing the root cause and preparing a prescription under guidance of the doctors themselves. This can easily tap into the existing doctor-patient consultation experience and enhance the outcome. Later on this can turn into a full fledged tech setup that can analyze test reports and scans as well. The system can automagically keep patient records and recall during followup visits (just from the patient's face), no manual data entry required.
There are ongoing research articles that quantitively measure the capability of ChatGPT given the proper context for medical diagnostic reasoning in randomised clinical trials. The result is already disruptive.
| Case | Diagnostic Accuracy |
|---|---|
| Doctors Alone | 74% |
| Doctors with ChatGPT | 76% |
| ChatGPT alone | 92% |
The study shares two challenges:
1. Overconfidence: Doctors often ignored ChatGPT’s correct diagnoses if they conflicted with their own. How can we get AI to explain the why and influence better without manipulating?
2. Underuse: Doctors are undertrained on AI and treated it like fancy Google. Rather than copying and pasting the whole patient history and diagnostic results in and “talking” to the data, they were using it to find relevant resources.
The bottomline is AI has the capability to revolutionise medical diagnostics, but only if doctors learn to trust, verify, and utilise its capabilities. Solving this problem can be a disruptive startup in this field.
Candidate Idea 2
Everyone knows our education system is broken. Tech is now available to fix it for all. But it still needs a visionary who can dedicate at-least 10 years of their life to right the wrong. Nope, taking physical courses to online won't help solve it, nor creating digital versions of age old coaching centers.
I believe, fast hands-on problem solving, then learning how the solution works is a more effective learning paradigm than learning everything through boring lectures for years before applying that knowledge into the real world.
I believe good education starts with the "whole game", where you get to know the why first, you get to know the problem at hand, you get to know the context why that particular concept emerged. You then learn hands-on different solutions, you learn how the context evolved. Even if you don't quite understand the solutions, you still experience the result the solutions bring. Then you start digging deeper to dissect each concept, understand the how, understand the science / evolution of it. You must first Start with WHY to connect the dots while you are learning.
As there are very few teachers in the world who has the courage and expertise to organise their courses in this way, the general education remains boring and students come out with "certificates" without acquiring real skills. But we now have technology that can scale those great human teachers, so that everyone gets access to that brilliant way of learning by doing and receive personalised care whenever the students need them.
Candidate Idea 3
Wanna buy something? You can just ask and let the system research, find the best product options you can buy, find the best deals available right now and autonomously notify you with best options. Just say yes to it and it proceeds to order that thing for you before it runs out of stock. It can also track deals, stocks etc, book flights, hotels, plan tours, choose restaurants and many more things for you and take autonomous actions while you're relaxing in your couch. It learns your preferences, predicts what you need when, research autonomously and comes up with the best option you need.
Candidate Idea 4
Agent takes notes, give feedback, brainstorm in business meetings. Helper slack/chat bot who analyzes all public conversations happening in a company, all meetings, track decisions / executions and suggests ideas and solutions to the hardest problems company is facing right now.
From a technical standpoint, at the very least, an llm mixed with agentic capability should be able to organize, implement and track a scrum/kanban process to efficiently manage a software team for work in progress and help deliver quality software on time. How about a psychobot conducting daily standups, prepare summary notes and alert me when things go south. Like a psycho micro-managing scrum master, the bot manages all the boring jira tickets and reminds the developers "every hour" to update the status of their jira tickets? At least, when devs curse someone, it's no longer a human which seems like a great achievement! However I'm sure CTOs like me would love that tool and cry "shut up and take my money".

Candidate Idea 5 and Beyond
Product sales automation? Growth and marketing campaign automation? Social media influencer? HR management automation? Code review / unit test automation bot? Test case generation and QA execution bot? The list goes on...
I must stop there. I can't do so many things, this is a perfect situation to procrastinate again. I need to focus on one single thing. But which one?! Help me...
I've now ended up procrastinating while waiting in my discord server for your feedback.
